Laws of Bangladesh and AI search(AutoRAG) by Cloudflare


Laws of Bangladesh are available at the government website here: http://bdlaws.minlaw.gov.bd/laws-of-bangladesh.html
Goals:
- Make the law content to be able to feed into AI model and train them.
- Or, make RAG(Retrieval-Augmented Generation) to answer question from the data source(in this case, Laws of Bangladesh)
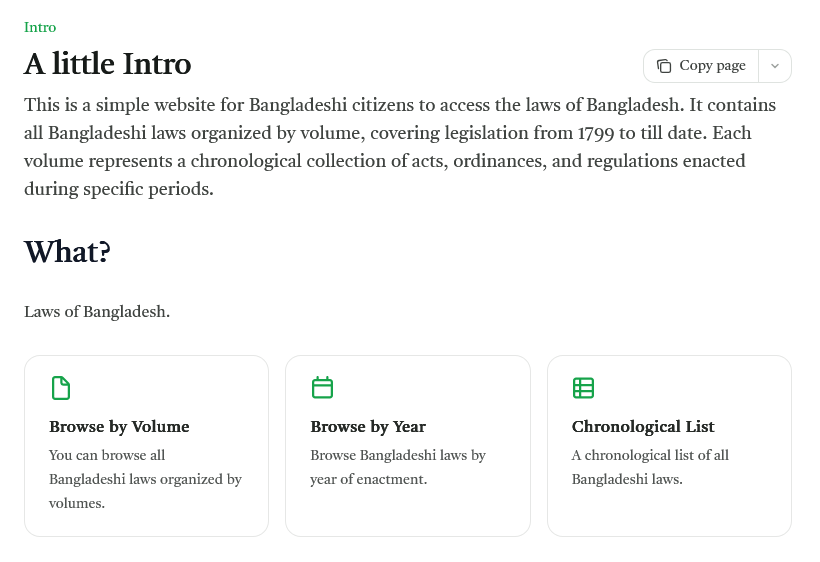
What I did:
- I found that someone already made few models here, here and here. And, a Kaggle dataset. I could use those but I didn't. I scraped the whole site: http://bdlaws.minlaw.gov.bd/laws-of-bangladesh.html
- Using the scraped data I built a website using Mintilfy CMS(Documentation Management software). I could use opensource documentation software like Docurus, mkDocs etc. But, I choosed to use Mintlify as it's free plan was enough for me to host the Laws. Also, Mintlify offers custom domain for free. I didn't take extra hassle to host them.
- Mintlify offer AI search using RAG but it's in their paid plan.
- Then, I discovered AI search (AutoRAG )by Cloudflare. It crawls all the content using the sitemap: https://laws.sayed.app/sitemap.xml and save them in R2 bucket.
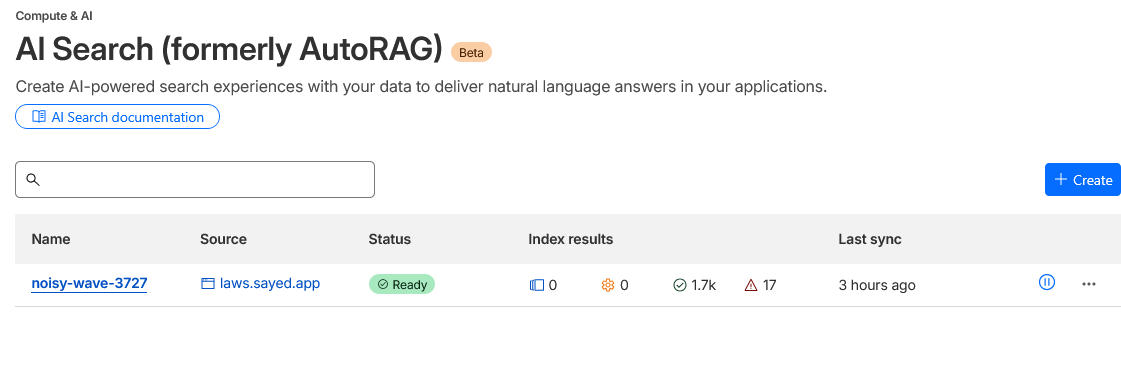
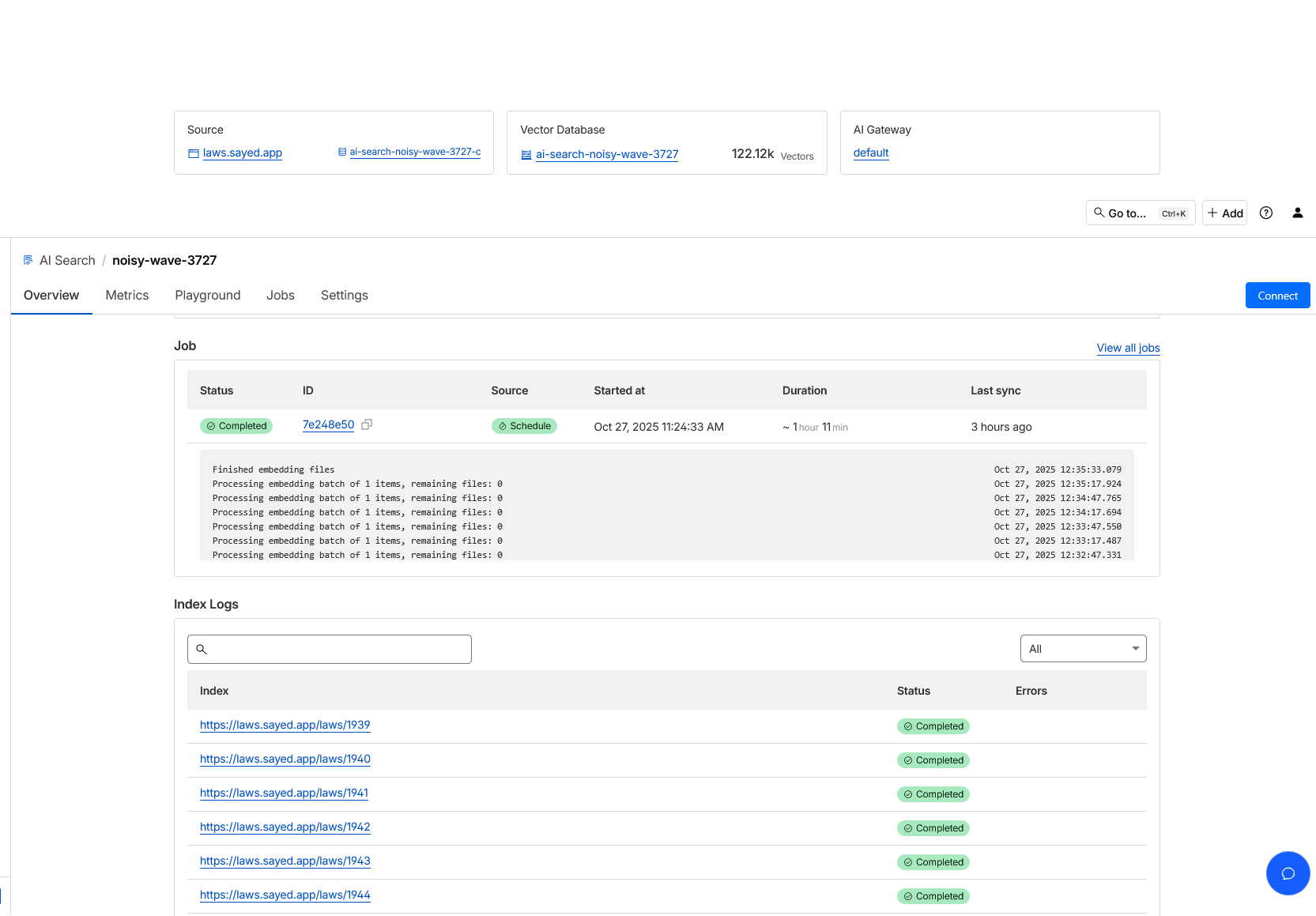
- Cloudflare AI search download every page and save them in a R2 bucket and make vector db from these pages. Which is not ideal and efficient for https://laws.sayed.app
- I used @cf/baai/bge-m3 model which was default. Model Documentation here. But, this model is not efficient and provide wrong answer! For test purposes, I used this model.
- All the Laws are also available in markdwon format from mintlify as llms.txt , llms-full.txt and Github repo. The llms.txt and llms-full.txt can be used as source for RAG. I may implement it on cloudflare later.
Here some stats from cloudflare:
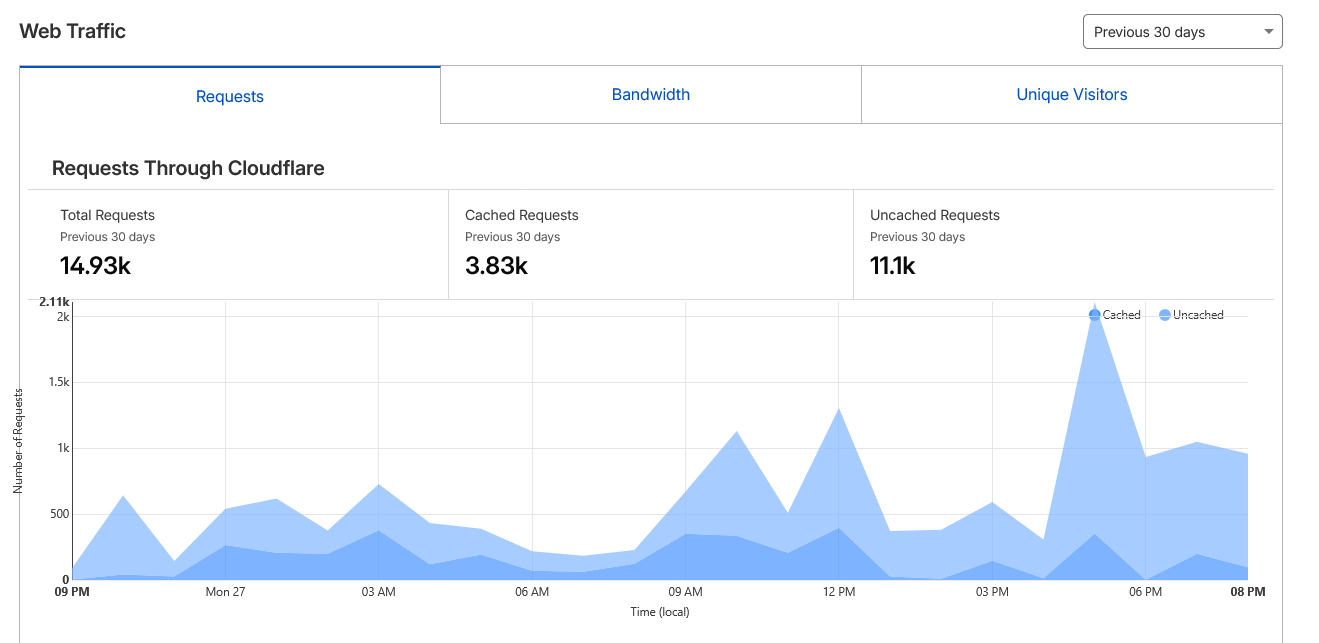
Idk, if these traffic are real or not but many AI crawler do crawl the site. Beside my root zone(sayed.app) have few subdomain so, traffic from other site may count.
Thanks for reading.
Note: This article was not written by any AI and this article may or may not help anyone.



